This is the third part of a series sharing Smithsonian Libraries and Archives’ work with linked open data and Wikidata. For background and overview of current projects, see the first two posts in the series.
As part of the Smithsonian Libraries and Archives participation in the Program for Cooperative Cataloging (PCC) Wikidata Pilot Project Wikiproject , we established the Chinese Ancestor Portrait Project (CAPP). Through this initiative, we set out to create Wikidata for 90 Chinese ancestor portraits in the collections of the Freer Gallery of Art and Arthur M. Sackler Gallery of the National Museum of Asian Art. You can see a list of these ancestor portraits on the PCC Wikdata Pilot Project page. One thing we wanted to do as part of our CAPP project was upload the images for these ancestor portraits.

Initially, our primary issue was Creative Commons licensing for digital images of the paintings. Wikimedia Commons only accepts freely licensed content or content that is in the public domain. While the Smithsonian is in the process of marking materials without copyright and other restrictions with a CC0 license in support of our Open Access initiative, not all collections have been fully researched and updated. Many of the ancestor portraits have not yet been assigned a CC0 license. However, some of the images for these paintings were previously uploaded onto Google Arts and Culture, and many Wikipedians had already grabbed those images and uploaded them to Wikimedia commons. Our solution was to work with the image set that was cleared by the National Museum of Asian Art for CC0, as well as the previously uploaded images, and then describe the paintings we could not use with a set of core and extended Wikidata properties.
Step 1: Creating sitter Wikidata item identifiers (Q#s) and pages
We began by creating Wikidata pages for the people represented in our portraits, or sitters. Early in the process, members of the Wikidata team decided on a core-properties to be used for sitters. These core properties, known as P numbers, correspond to basic biographical data that help to describe the people represented in our paintings.
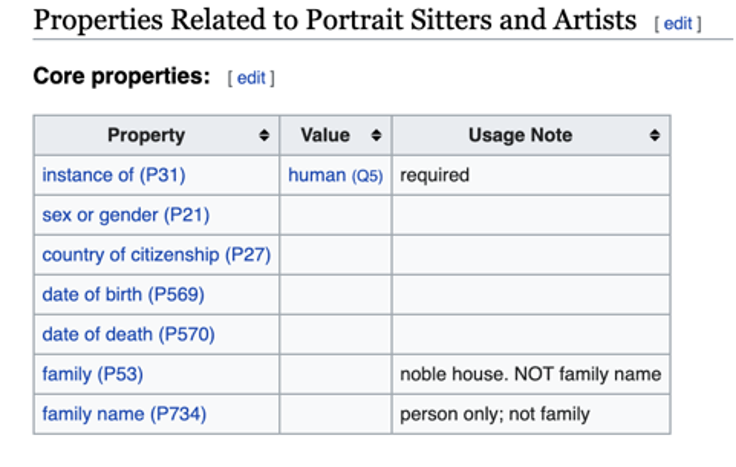
We grabbed as many extended properties as we could find through our research. This included additional biographical information about familial relationships, birth, death, location, accomplishments, rankings, etc.
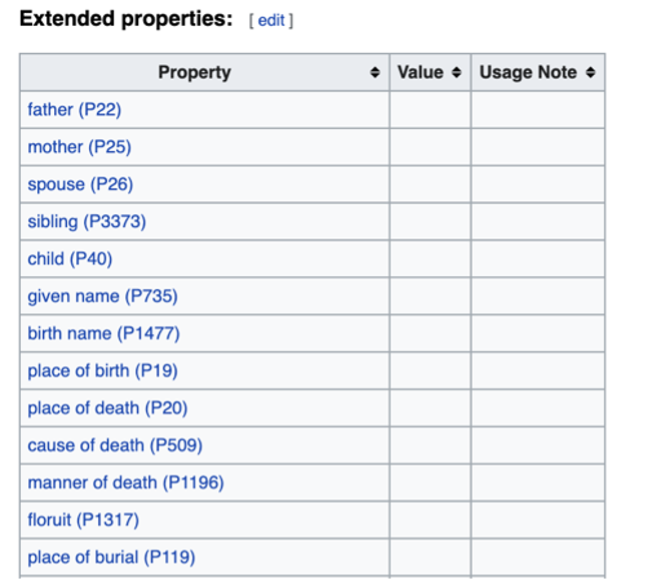
Step 2: Creating Painting Q#s/pages
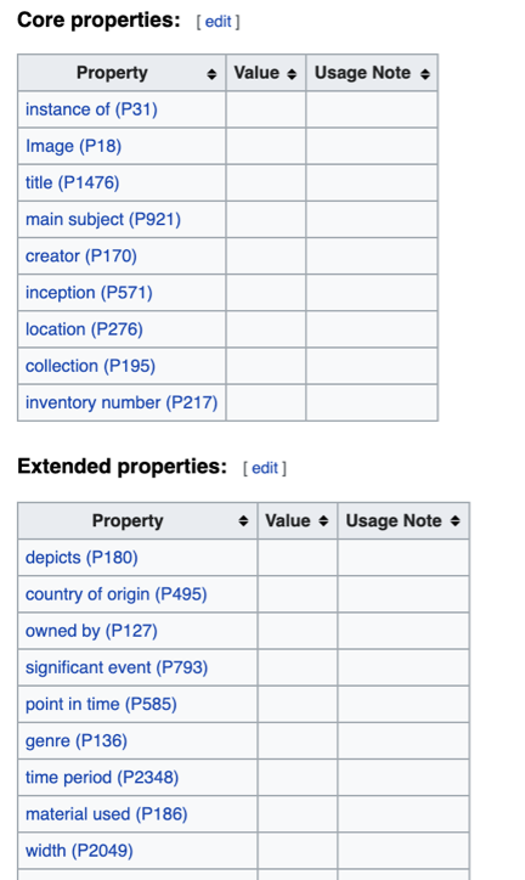
The next step was to create Wikidata pages for the paintings themselves. This establishes them as separate independent entities, using an entirely different set of core and extended properties related to artwork. Information was taken from public-facing Smithsonian sites like the National Museum of Asian Art collections website and the Smithsonian Collections Search website. These properties are common descriptors for museum catalogs and curatorial notes, creating a shared vocabulary across institutions.
Step 3: Uploading to Wikimedia commons
Example 1: Previously uploaded portraits
Once the team had created Wikidata pages for each of the sitters and each of the paintings, I started by using painting titles and sitter names to comb through Wikimedia Commons. Once found, I used the Template:Artwork to augment existing data in the item summary on the commons page. The template includes much of the same information as our core properties and allows us to redirect searchers to our own catalog for better images and more information. This is particularly important because these portraits were often wrongly attributed to other collections outside of the Smithsonian.

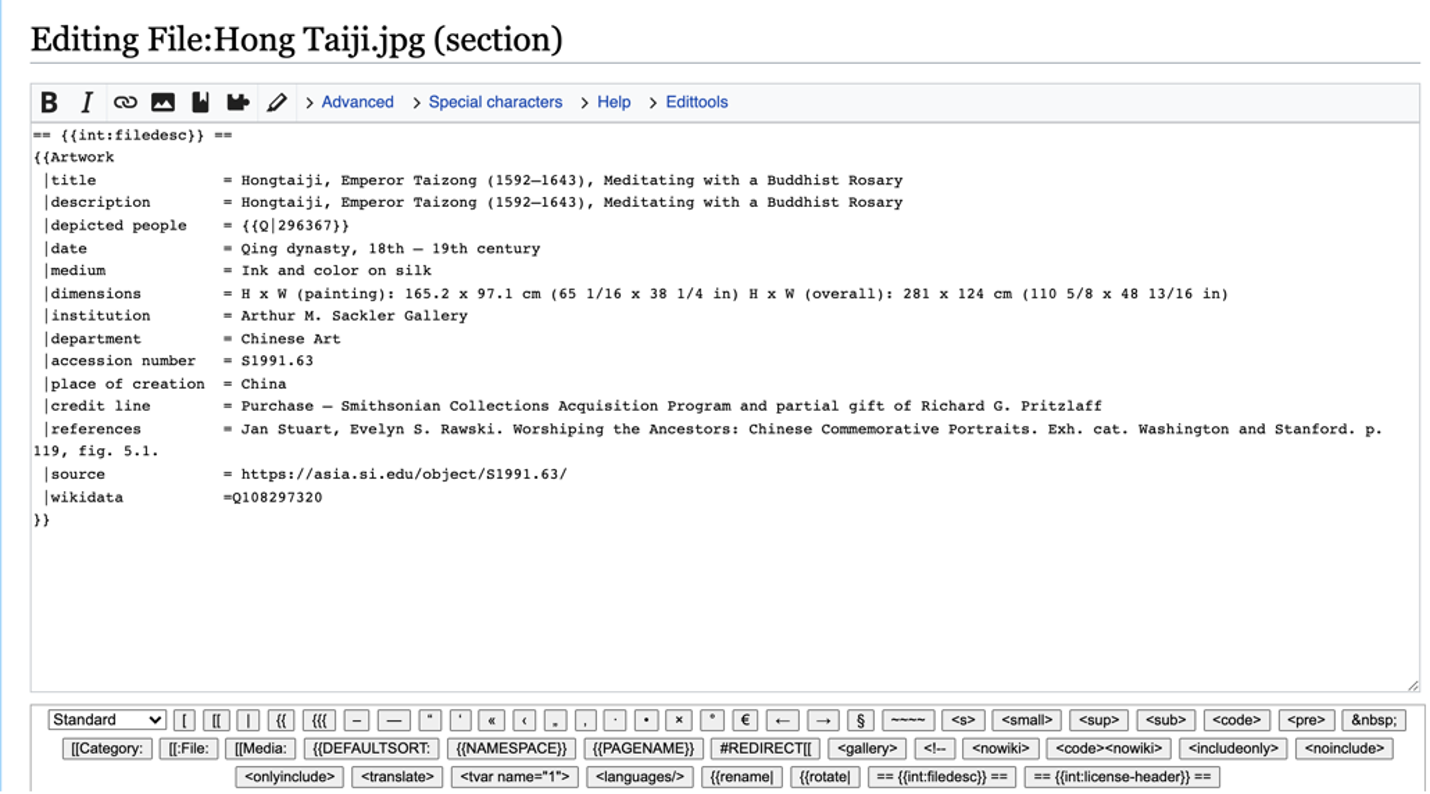
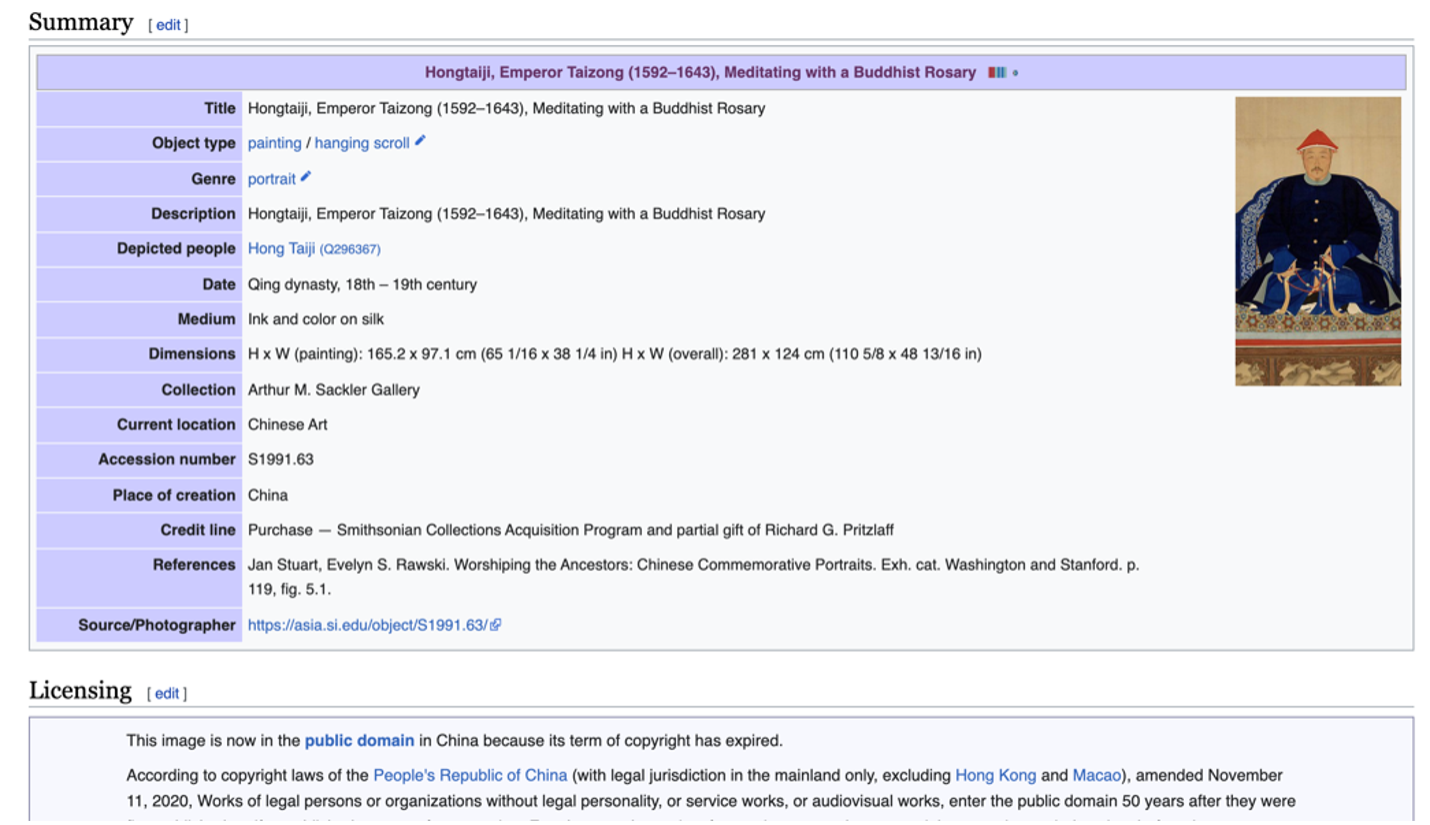
Notice that the inclusion of the Wikidata Q# for the sitter (Q|296367) populates a hyperlink to the Wikidata sitter page!
Example 2: Uploading new images to Wikimedia Commons
First, I needed to grab the hi-res images from the public-facing Smithsonian collections sites. Again, I only uploaded those images that already had a CC0 license. Using the Commons “Upload File” tab, I would upload them image, and then enter in the corresponding web address for the image, as well as any available artist information and the CC0 license.
The next step was to add basic description information. I kept the description short, usually including the title, time period, medium and accession number.

The following page asks for optional metadata using Wikidata P#s. Again, I referred to the core and extended properties we established for the painting Q#s. Wikimedia commons links this structured metadata back to Wikidata, pulling relevant Q# values where applicable. Users need only search for the value in the box provided.
The last step was to edit the summary info box on the resulting commons page for the image using template:artwork again. You can view the sample completed page here.
Step 4: Linking the Pages
After the Commons page is created, I linked the Commons images to both the paintings Q#s and the sitter Q#s through Wikidata. In both pages, I added the statement Image and searched for the title of the uploaded file. This can sometimes pull a lot of different images, especially since we were dealing with many important and well-known historical figures who have multiple likenesses in existence. It was best to actually save and input the exact file name. The result of adding the image to these pages is that it links the Wikidata page to the Commons page, and allows searchability through either portal. Ideally, rather than having to enter this data by hand, it would be better if future updates to these platforms could pull the structured data in from Wikidata and populate it in the Wikimedia Commons.
The end result of this project is that all of these pages “talk to each other” because of structured data and provide new discovery access points for objects in Smithsonian collections. By its very nature, new and improved access and discovery mechanisms are possible, connecting objects (works and persons) found in the Smithsonian collections and beyond. In searching through English (and sometimes Chinese) language Wikidata and Wikimedia Commons you can now find the portraits, sitters, and their descriptive metadata. More importantly, we provide the accession numbers and links to our Smithsonian-hosted collections sites to help researchers find and use our collections.
One Comment
Great job! Thank you for contributing to Wikidata!