This is the fifth part of a series sharing Smithsonian Libraries and Archives’ work with linked open data and Wikidata. For background and overview of current projects, see the first several posts in the series.
Failure
When pursuing data projects, sometimes failure is the most successful outcome you can have. Perceived “stumbling blocks” you may encounter can profoundly teach you about your data, your projects, and what it is you need to course correct (as well as how much resource you may be lacking!). Our Smithsonian Research Online experience with Wikidata is a perfect example of one such learning opportunity.
Linked data
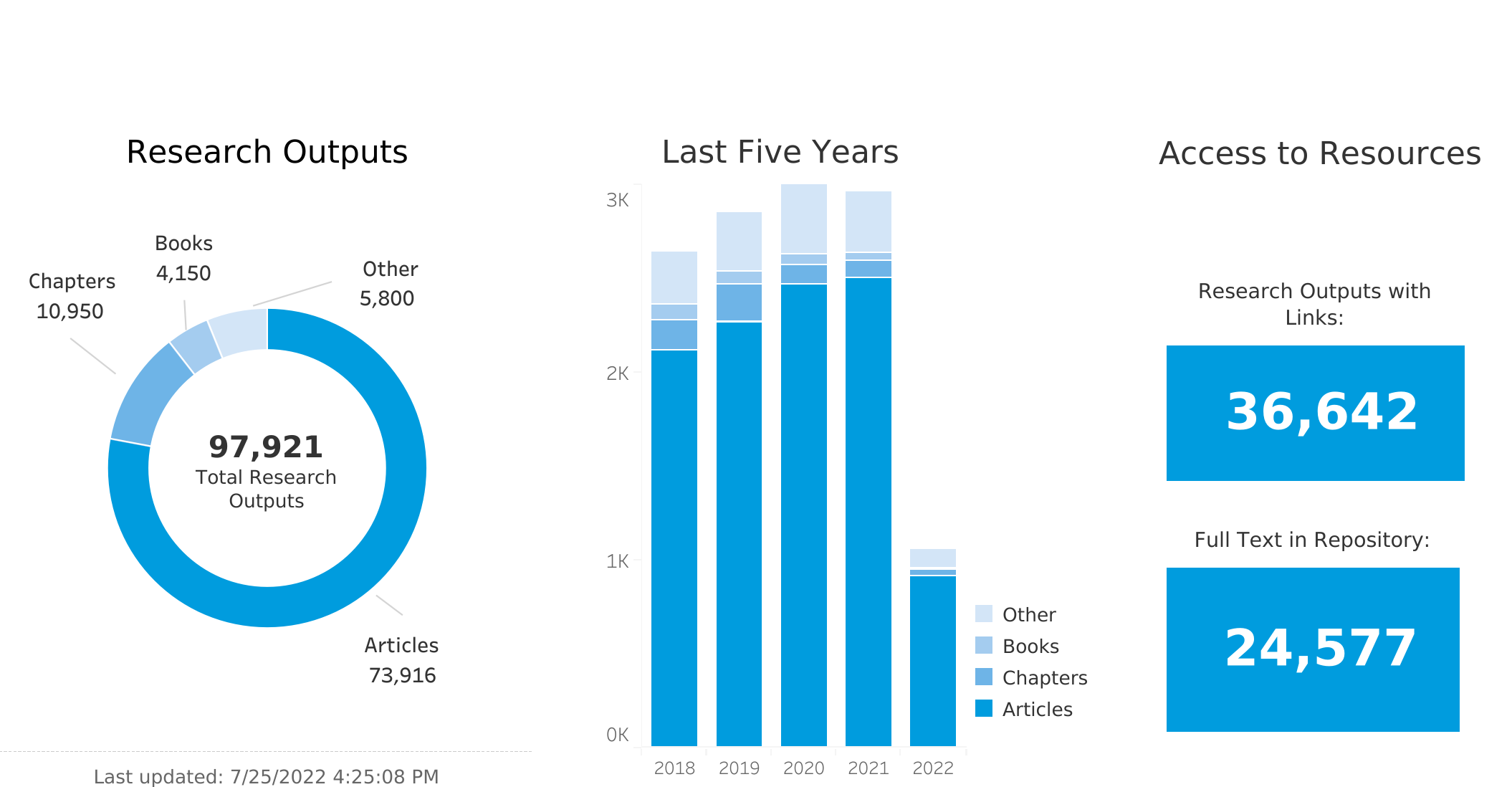
As research information management professionals, our team is knee-deep in the types of data that Wikidata was built for. The Smithsonian Research Online program at the Smithsonian Libraries and Archives has collected and managed data about the research published by scholars at the Smithsonian Institution for almost fifteen years. We now are just shy of 100,000 research outputs ranging from journal articles, book chapters, and books, to guest lectures, blog posts, and even a few patents. Along the way, we have identified over 150,000 distinct agent names found within this bibliographic corpus and have maintained a minimal ability to associate those names to individual persons. But the workflows and the technical support needed to maintain them are both taxing. So, when the opportunity arose to learn about the wiki-world and its promise for helping us with authority control, the Project for Cooperative Cataloging Pilot naturally interested us.
Tools
Bibliographic data in Wikidata is so important that many tools have been developed to help move us forward. Aside from the myriad existing projects and bots importing bibliographic datasets into Wikidata, the Scholia project is a notable example of how bibliographic data, once in Wikidata, can show off amazing stuff. In fact, they use the Smithsonian as one of their examples for organizations. As Scholia relies heavily on Wikidata’s bibliographic content, linking the publications to their authors becomes a key component of enriching this data. One tool for doing so is the Author Disambiguator. The importation of metadata from sources like Crossref is easy enough, but it takes some brain power to make sure that the author named in the paper is a specific person with an item in Wikidata. That is where the author disambiguator comes in: it allows someone to run a fuzzy search on a name and then groups results in a way that most likely indicate the same name. From there, it is a matter of replacing the statement on a publication’s Wikidata item that holds the name string with a statement that actually associates and connects the publication to the author’s item itself in Wikidata.
Of course, none of our work could be done without tools like SPARQL query service, QuickStatements, OpenRefine, and more. We used each tool extensively. The SPARQL query service allowed us to evaluate what was in Wikidata already. For example, when working with organizational data about the Smithsonian, we needed to see what belonged to the Smithsonian, and SPARQL allowed us to visually graph the entities. We could also use Listeria to generate tables with the core properties we were looking to ensure were correct in Wikidata. OpenRefine’s reconciliation service was something we used often to process our data about organizations and people. Finally, QuickStatments made easier work of ingesting more than a few records at a time.
What we hope to do with this (Failure Continued…)
When we set out on our ambitious collaboration with the Project for Cooperative Cataloging, we hoped to start by cleaning up Smithsonian organizations, then add Smithsonian authors, and finally populating with Smithsonian publications—a big project with even bigger questions.
We accomplished a lot of these tasks. First, we made sure that the organizations in Wikidata for the Smithsonian were represented, had authoritative data about them including external identifiers, and that they were properly related to the Smithsonian itself—an element of belonging that can be difficult to maintain in Wikidata. However, the actual process of fully modeling organizations and buildings posed more challenges than we anticipated. After all—what is a museum? Is it an organization that occupies a building? Or is a museum a building that holds exhibitions?
In some cases, the distinction between building and organization was clear—we have two museums (the Smithsonian American Art Museum and the National Portrait Gallery) that occupy one building (the Old Patent Office Building, now known as the Donald W. Reynolds Center). But what do we do with the ones that were treated as both a building and an organization? This posed real challenges, especially as the Smithsonian now has two new museums that are a decade away from finding a home in an actual building. So, the inception date for these museums is often quite different from the opening date, and statements are not consistent across our museums. This can make using the data challenging since you cannot easily query things based on a consistent set of properties. Additionally, the matter has yet to be settled within the Wikidata community, where there are arguments for and against establishing separate entities for items which currently conflate buildings and organizations, especially when the building does not have its own unique name. Solving this problem is not as easy as creating those separate items ourselves, as other Wikidata editors who disagree with the practice may merge our newly created items back into one conflated entity. We continue to refine our approach.
Next, we made sure that our researchers had entries in Wikidata. Happily, we found that most already had them, thanks to past projects between the Smithsonian and Wikidata. However, the project posed a challenge: Who should we focus on? Many staff members across the Smithsonian coauthor publications even if their primary job duties do not include research. There are countless fellows, post-docs, pre-docs, interns, contractors, and affiliated agency staff who do work and publish at the Smithsonian. Finally, there are plenty of researchers who have an affiliation with the Smithsonian even if they are not employed or located here. Do we represent this information in Wikidata? If so, how far back do we go? (Or do we even try to be retrospective?) This was a decision we needed to make, joining the many other decisions we were presented with along the way, resulting in a bit of decision fatigue. We did have a logical set of data, though—we have an existing linked data project in the form of our VIVO implementation, Smithsonian Profiles. At the very least, we made sure the people in our profiles were also in Wikidata, with some core properties to at least associate them with the Smithsonian.
The area we failed in accomplishing was how to ensure that publications from these researchers were properly included in Wikidata and properly attributed to the person. For example, we did queries in our system for the researchers in Smithsonian Research Online who had the highest number of co-authorships, and began to run the Author Disambiguator to associate each author’s Wikidata entry with the publications that had that author’s name as a name string. What this does is find a name string in the author name string property statement for a publication, lets you determine if it is a known author with a Wikidata entry, and then it removes the name string from the author name string property and adds the correct Wikidata item for the author in the author property statement. This truly links the publication’s Wikidata item to the author’s Wikidata item, thus creating a much richer knowledge graph and enabling things like Scholia to work. Even with the increased efficiency of using the Author Disambiguator, a project to associate thousands of researchers with thousands of publications still requires a lot more staff time than we had available to pursue.
Ambiguity solved by Wikibase?
We may not have perfected our data representation in Wikidata, but what it offered us instead was a robust introduction to data modeling and figuring out the potentials of the Wikibase software in generating linked data. Now that we have some representation of our researchers within Wikidata (and at least know the fundamentals of how this works), our next experiment is to take those researchers and create a local wiki ecosystem that can connect to Wikidata, but still offer us the ability to control the exact set of data points we want to add for each researcher—which would help us immensely when we need to deal with two researchers sharing the same name, or when researchers have multiple names in the literature—whether from different abbreviations, naming conventions, or changes in names. One of the persistent challenges for bibliographic data is associating and teasing apart ambiguous names. One author can have their name listed in many different versions – especially if their name changes from marriage, gender transition, or even from variations in citation style abbreviations. (Not to mention how names in publishing are often shoehorned into western conventions, as explored for Vietnamese names in this Twitter thread.) On the other hand, you can have multiple people with the same name (even at the same institution!). Having a platform like Wikibase could allow us to maintain those distinctions, and then relate our data to the appropriate person’s record.
The potential strength of Wikibase lies in the flexibility it offers to accommodate local modeling of data. In the case of Smithsonian organizational data and the relationship among our different museums, research centers, and other units, having a locally installed Wikibase gives us complete control over how we model our data while still linking with rich external sources of information. Wikidata is a revolutionary experiment in democratizing data. The benefits of removing gatekeepers to data are many, and we are excited to see the fruits of this. Yet it is clear we aren’t quite ready to fully commit to tearing down that gate. We still need (at the very least) a garden border, so we can tend our own data the way we see fit. Can Wikibase provide that service for us? We shall see.
Be First to Comment