As a current graduate student studying for my Master’s in Library and Information Science, I have a passion for digital archives and information organization. Throughout my own research, I have identified the importance of digital preservation and access to information and data. For my internship I worked with the Smithsonian Institution Archives Digital Services staff as part of the Smithsonian Libraries and Archives Summer Scholars Internship Program.
When I first started this internship, I had the objective of learning more about the process of digital archiving and storing data. I had minimal knowledge of web archiving services and tools. This internship has broadened my knowledge beyond web archiving services while learning the importance of using various tools in order to improve the process. Learning ways to improve the collection and organization of stored data are important for correctly preserving the metadata and digital assets. My goals for this internship were to increase my knowledge in Dublin Core metadata schema, learn how to use web archiving services, and organize metadata. During my internship, I have learned new vocabulary along the way throughout the steps of the web archival process.
The workflow of metadata needs to be organized and precise. The collection that I have mainly worked on is the Smithsonian Institution Websites collection, which consists of Institution websites that have been crawled. Information also is updated within the Smithsonian Institution registry. The registry is an internal document that helps with tracking the Smithsonian websites and social media accounts. Over time, it is important to update this information due to the frequent change in contents on the web pages.
The main web archiving service we use is Archive-It, which is owned by the Internet Archive. It captures and preserves online electronic resources with a focus on access. Throughout my internship, I also was exposed to other web archiving services and tools, including Webrecorder, Conifer, Browsertrix, and Netlytic, to assist with the archival process to provide accurate crawls of each web browser.
There are many web and social media archiving terms I have learned:
- Seed: a URL to be crawled.
- Scope: an extent that the crawler will travel to discover and archive new materials captured.
- Crawler: collects majority of the contents in the data found from the web.
- Capture: the process of copying digital information into a repository for storage, preservation, and access purposes.
- Brozzler: crawling technology capturing dynamic contents.
- Quality Assurance: review of the crawled site compared to the live site.
- Accession: unique number assigned to specific group of archival materials.
- WARCs: international format standard that combines multiple digital resources into an archival container file.
- Host Lists: captured information of each host (storage of web content) site that has been crawled.
The use of the Open Archival Information System (OAIS) reference model has broadened my perspective of how each Archives’ team member works on their preservation workflows as web pages change constantly, such as managing the metadata, curating, and storing the information, and then providing access to the information for both staff and the public.
Throughout the archiving process, Dublin Core, a metadata standard for a wide range of networks and resources, is used to fill out descriptive elements within the Archive-It records to enhance the search and retrieval of archival collections. Creating an online listing of the Smithsonian Institution Websites is a way to have an available electronic bibliographic database that describes the content that each website and social media store. Since social media is very tricky to archive due to the dynamic content being showcased, using multiple tools to capture the data is important because it makes the web crawling process easier. Whenever any technical issue occurs there is always room to search for other alternatives to assist in the process that may seem to be the most appropriate based on a particular archival project.
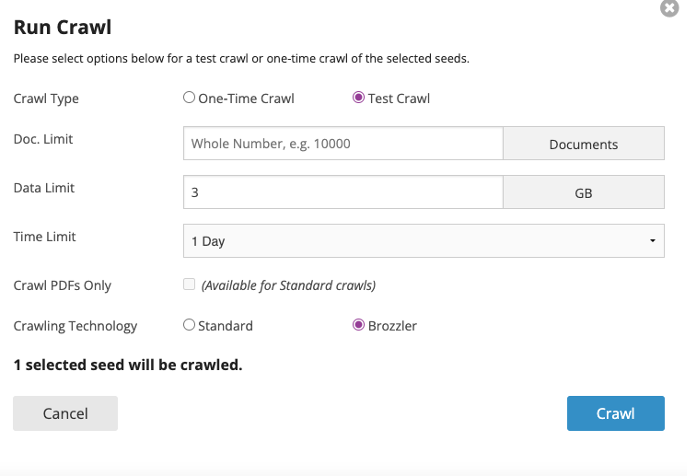
This is an example of a crawl that has been added through using Archive-It. Parameters include limiting the size and how long it should run:
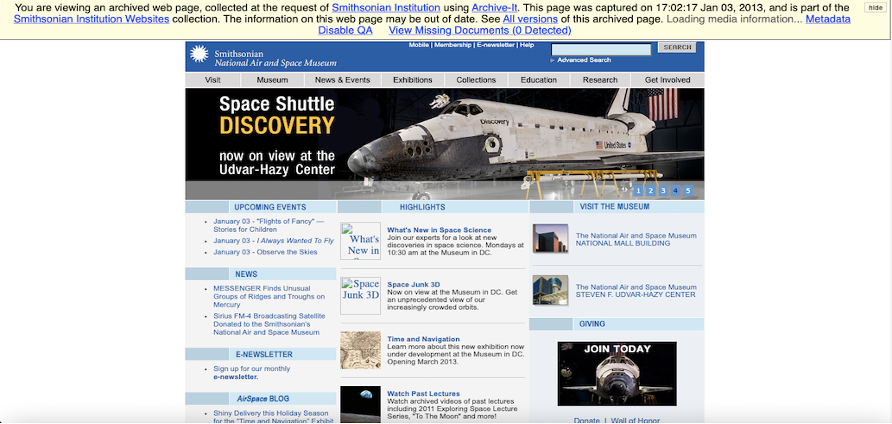
This is one of the examples of a previously crawled Smithsonian website with Archive-It for the National Air and Space Museum from January 3, 2013. Notice the images, web page layout, and logo on the website compared to the next crawl.
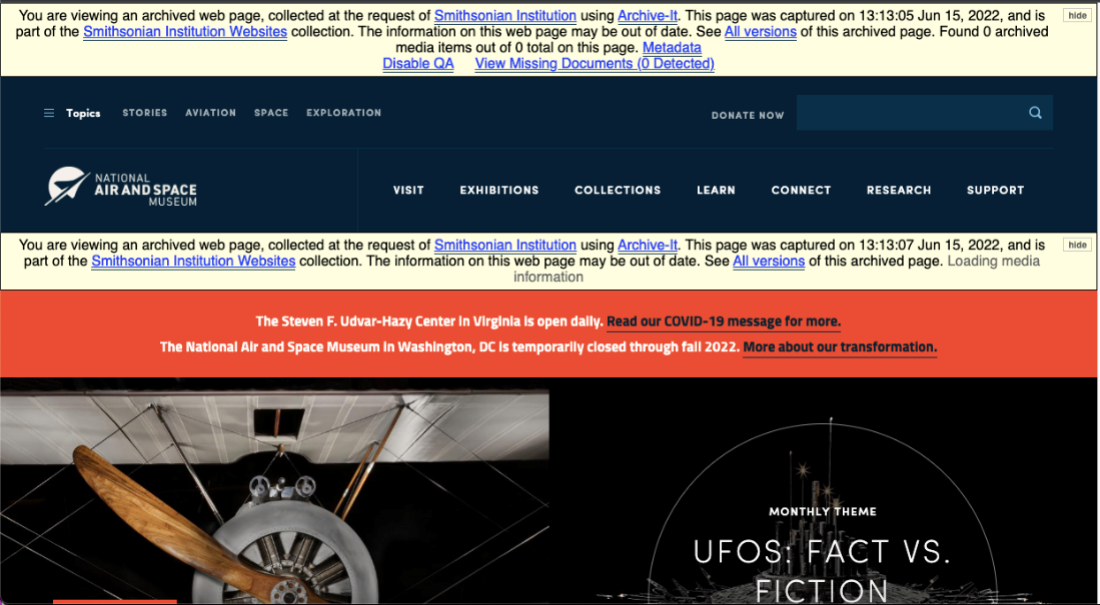
On June 15, 2022, I crawled this website. See that the newly posted images captured at the time and the logo are updated. Having this information digitally archived is important to have a way to look back at Smithsonian websites and to have them historically documented for the future.
When I went to American Library Association Annual Conference 2022 in Washington D.C., I stopped by the Archives’ office. It was wonderful to meet the team in person and take a tour with my supervisor. I was able to meet with the digital archivists to see firsthand some of the archival processing being done on the website collections that I learned how to capture as part of my internship.
Did I mention I saw boxes of floppy disks waiting to be copied and pallets full of boxes of Smithsonian collections waiting to be processed? Fascinating, right?

Throughout this internship, I have gained a real-world perspective of digital archival works. This experience has prepared me for the aspect of the digital archive workplace. My passion for digital archives has increased and opened my mind to possibilities to advance my technical and archival skills. Working virtually with the digital services staff has been an adventurous learning experience. Although I have gained real-world skills in web and social media archiving, digital curation, metadata, and digital preservation, I always still have the desire to expand my knowledge further.
Be First to Comment