
Open Access Week is the perfect excuse to talk about a favorite topic of mine—making Smithsonian research more open! A couple years ago, I wrote a post about a Tableau dashboard released by Smithsonian Libraries and Archives that explores the Open Access status of publications from Smithsonian-affiliated authors. Since then, we have taken things a step further, using the same source data to enhance Smithsonian Research Online directly by including links to open access versions of Smithsonian journal articles thanks to Unpaywall’s API. This means we have added over 8,000 links to journal articles anyone can read regardless of affiliation.
Smithsonian Research Online is a Libraries and Archives program to track the research output of the Smithsonian. With nearly 100,000 records, the system spans the life of the Smithsonian, with an average of 2,500-3,000 new records added each year. One of our goals with Research Online is to make sure that this research is accessible and available to fulfill the mission of the institution—”the increase and diffusion of knowledge.”
For the past few years, we have been using Unpaywall’s openly available data about the open access status of journal articles. Their API includes a status designation for the different ways in which journal articles are accessible. As you may know, the traditional model of scholarly publication is that authors submit publications to a journal, and that journal will charge for access. Much of this cost burden has been borne by libraries in particular, as we want to make as much available as possible (naturally!). This is what “closed” means in this context—it’s in a journal you need to pay to access.
Beyond that, there are many ways in which a journal article can be “open.” This includes journals where the entirety is freely available (often referred to as “gold” open access), individual articles made available for free in an otherwise for-pay journal (deemed “hybrid” by Unpaywall if there is a specific license for availability assigned to the article, or “bronze” if no such license exists but it is still available without paywalls), and finally articles can be made available in a digital repository (“green” open access), where a version of an article is accessible to the public.
These colorful terms can be simplified into two camps: open or closed. Librarians know that users care less about the distinction than we do, but we really care about the distinction! It helps us assess where scholarly communication is going and helps us think about where to put our often-diminishing resources.
Beyond simply analyzing our content, in 2022 we took things a step further by integrating data from Unpaywall directly into our system. First, we looked at what data was available from Unpaywall. Their API provides links for each way a research article might be open access—whether it was in a journal that is open, or in a repository where a researcher shared it. They even include many that are both open from a publisher and also deposited in multiple repositories. (As of today, there is one article that is available openly from the journal but also deposited in 63 separate repositories! To each their own…) We took this data and determined that we needed a separate table in our database to handle links from our different data sources: Unpaywall, links we already had to our own digital repository, and links that come from the original ingest of metadata (via Zotero or our own internal webforms). With these multiple sources, we decided on a hierarchy of which link to include in our results. First, we wanted to link to our own copy of something in our repository. If that wasn’t available, we felt the next best link to add was from Unpaywall. Finally, if we had neither, we would go with the link provided, even if it wasn’t always a link to an open access copy. Thanks to our data developer Kristina Heinricy, this whole process of taking our publications, searching for them in Unpaywall, and getting back the multitude of possible links has been fully automated and integrated into our system. This has resulted in over 8,000 new links to fully open content being added to our records!
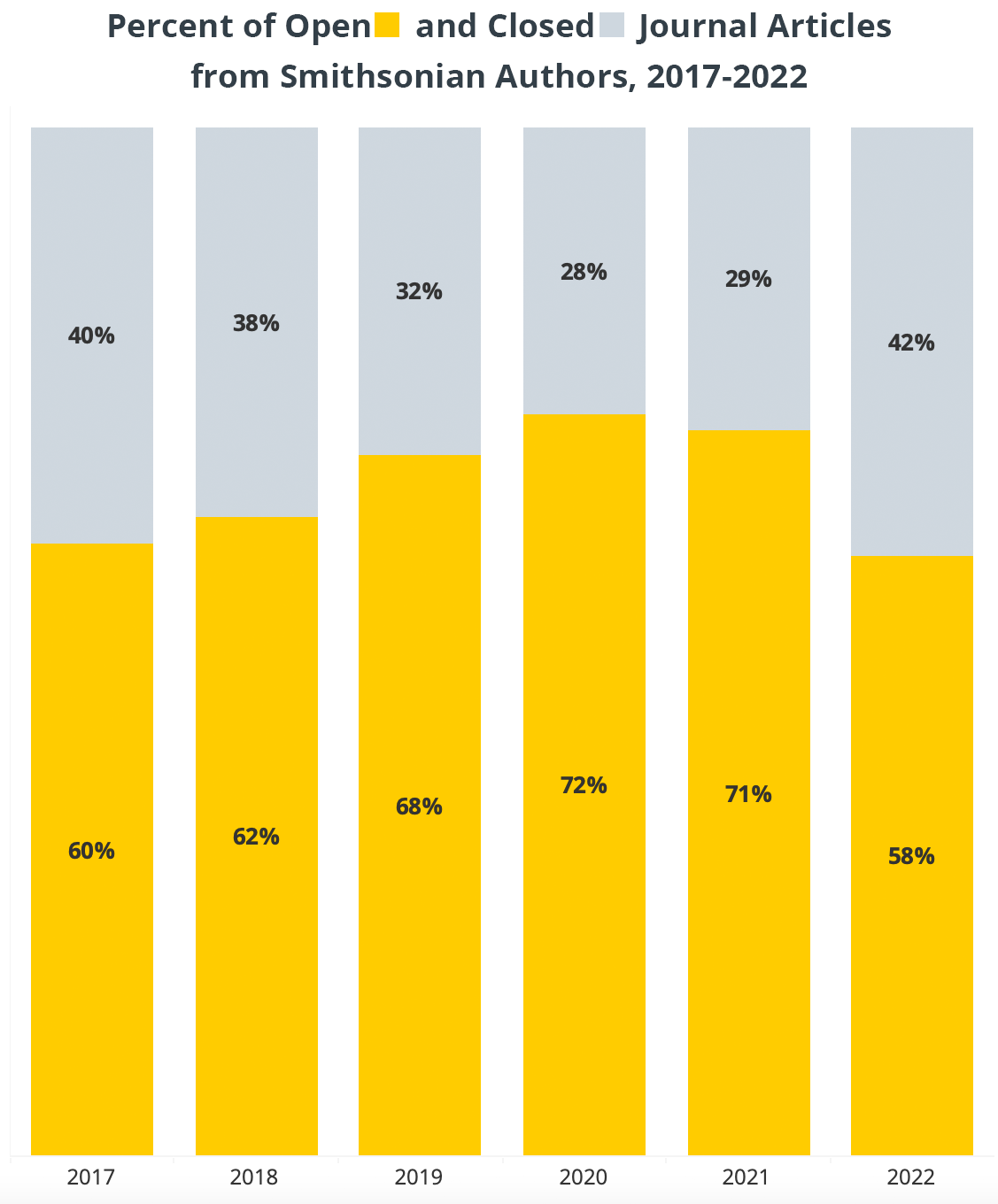
Many Smithsonian scholars are making their research open by publishing their papers in open access journals or making it publicly available in repositories, either because grant funding mandates it, they are dedicated to public access, or simply because an open access journal is the best journal for their research. Of course, the recent OSTP guidance making federally funded research immediately available plays no small part in this. Regardless of the intentions for publishing, the trend is undeniable. While embargo periods on sharing and the general lag in time for making articles available in repositories is evident in 2022 and some of 2021’s bars, this chart demonstrates that more Smithsonian research is available today than five years ago.
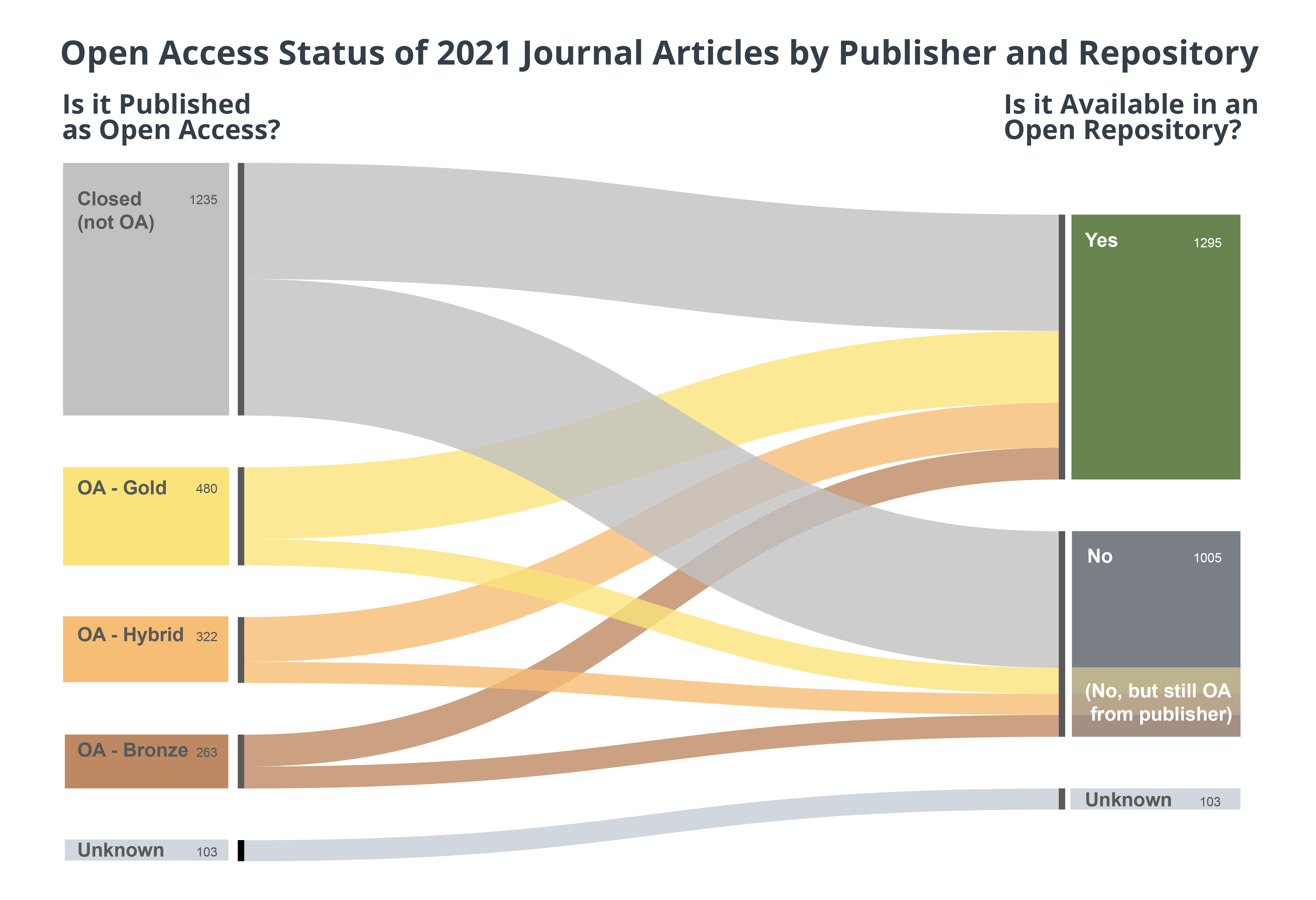
While we don’t capture the exact date and time when articles become open access, there is an inherent time delay between when something is published as open and when it becomes open through depositing it in a repository. We can visualize that time difference using an alluvial diagram. This one I made using RAWGraphs.io (with some tweaking in Illustrator). It helps to tease this out for a couple of reasons. First, we can distinguish things published open and things that end up open via repositories. But the interesting aspect to me is the overlap of items that are published as open and presumably will remain open that end up in a repository. It seems like an obvious redundancy. While it is not discouraged, I would much rather see more of the closed articles end up in repositories than open ones!
Now that we have this data, the future beckons! There are more ways this data could be put to work. One way might be to upgrade our user interface to point out which items are open and which are still behind paywalls. It should certainly relieve the labor of one-by-one evaluations of items. If the object is open, then maybe we don’t need to rush to deposit it in a repository as it is easily accessible already. I’ve pointed out some trends that I’ve seen, and some hopefully interesting insights. (You can see more about the program in our Annual Reports, too.)
What would you like to know about Open Access? Where would you like to see us take this?
Be First to Comment