
This is the fourth part of a series sharing Smithsonian Libraries and Archives’ work with linked open data and Wikidata. For background and overview of current projects, see the first several posts in the series. This post was written in collaboration with Nilda Lopez, Reference Librarian at the Cooper Hewitt, Smithsonian Design Museum Library, and a valued team member of the Artist Files Wikidata Pilot Project.

The Smithsonian Libraries and Archives’ Art and Artist Files collection is a dynamic and valuable resource for art historical research. In total, the Smithsonian has hundreds of thousands of physical files, containing millions of ephemeral items: newspaper clippings, press releases, brochures, invitations, and so much more. The files hold information on artists, art collectives, and galleries, but in formats that would normally have been tossed out, being too small to catalog and shelve in a library in the usual way. Because these special items fall between the cracks of typical library and research organizational practices, libraries that collect these materials are coming up with innovative ways to make their contents discoverable to a wider world. Which made them a wonderful collection to experiment with as a part of our Smithsonian Libraries and Archives Wikidata pilot projects!
Using our existing “home grown” database that documents the Smithsonian’s Artist Files from across the libraries, the goal was to incorporate our data into a more collaborative and accessible view of the collections to allow staff and our users to know we had research files on specific artists. In a linked open environment, we were curious if we could not only provide better access to our staff as well as researchers outside of the Smithsonian, but in the future to also track their locations and growth in a more holistic approach. This resulted in WikiProject PCC Wikidata Pilot Artists Files – Wikidata.
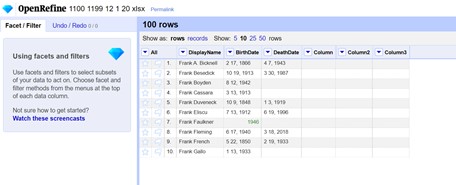
From our large dataset of nearly 60,000 artists’ names, our pilot project was derived from two Smithsonian art-related databases: the American Art and Portrait Gallery Library (AAPG)’s Art and Artist Files and the Smithsonian American Art Museum’s artist database. This cross-reference resulted in 3797 artists in our pilot dataset, which was the perfect number for the team to learn to reconcile, edit and add descriptive data to Wikidata itself. With this set of artists’ names, we played with different workflows and tools, and this post gives a sense of the steps in our final pilot project.
Reconciling and Wikidata with Open Refine
Data analysis is essential for ensuring information accuracy and quality, and reconciliation is usually the first vital step in the data analysis process. Our plan was to reconcile our pilot list of artists with Wikidata, to see who already existed! To do this, we used Open Refine, a free, open software that can “clean” messy data and connects your data points to many different sources. Within Open Refine, we searched our artists’ names and life dates to see if they already existed in Wikidata, as well as several other repositories, such as Library of Congress Authority Identifier, Virtual International Authority File, and the Getty’s Union List of Artists. Like all entities in Wikidata, those artists that were already in the system were represented by a unique identifier called a “Q ID” or Q number. You can read more about the structured system of Wikidata on the website Minding your Ps and Qs.
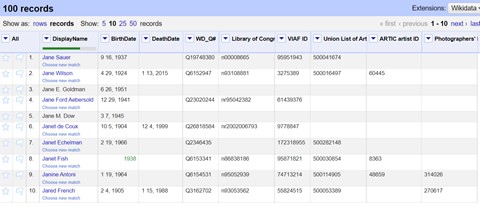
In addition to matching our artists with those in Wikidata, we also created a “wish list” of data points contributed by other institutions that we wanted to extract, properties like an artist’s place of birth or death, or what other museums own their artwork. Open Refine let us export all these data points into a spreadsheet to work on our later steps.
Data prep for NEW Artist Name Wikidata Creation
Our reconciling process matched a larger number of our artists to Wikidata, but many were not found in our initial search. What to do about those artists?
Several discussions helped finalize a list of core criteria properties we felt should be in all new Wikidata entries for artists in our Wikidata project, and how they’d best fit into its existing structured system of properties. When we found that we had a need that was not yet represented in Wikidata, we worked with the wiki community to create one that could be used by any institution with similar resources: a new property to note an artist has an artist file about them at a particular library. And as we created new Q numbers for artists, to better track our pilot progress we included a special identifier to show these names were on our pilot project focus list.
After a painstaking research process to confirm data points, these were then uploaded via Open Refine into Wikidata, creating brand new Q numbers for our artists, and helping build out the linked open world of art research information.
Adding our Core Properties into existing Wikidata entries via QUICKSTATEMENTS
Because we were able to match our artists’ names to many already in Wikidata, we had a much smaller batch to create from scratch. However, that also meant only the newly-minted artist Q numbers had those core properties that our team wanted to include. To fill in the rest, we used an easy, free tool called QuickStatements that allows anyone to bulk-upload new statements to Wikidata items.

After learning and experimenting, and a lot of work, the team’s combined efforts successfully connected all 3797 artists’ names in the pilot to Wikidata! We created a workflow that could be used in the future, and all gained skills and a better sense of just how linked open data can be harnessed to open up our research resources. We hope this experience will benefit the Smithsonian Libraries and Archives in the larger project to enact our own Wikibase, a collaborative knowledge base to manage all of our own Smithsonian Ps and Qs.
3 Comments
[…] Smithsonian Libraries and Archives & Wikidata: Adding Artist Files to Wikidata (Smithsonian Libraries and Archives) […]
[…] Smithsonian Libraries and Archives & Wikidata: Adding Artist Files to Wikidata (via Unbound) […]
This is fantastic! Congratulations.